今天從Token embeddings 開始繼續看
這篇大概涵蓋以下部份
Token是文本中的基本單位,例如一個詞或一個字符。在模型中,我們通常不直接使用原始的token,而是將它轉換成一個向量,這就是所謂的embedding。這段的目的是向我們展示如何取得這些token embeddings。
其中有一個get_input_embeddings的函數。但這個名稱可能會造成一些誤解,
因為這些token embeddings在實際被用作模型輸入之前,需要與position embeddings組合
在文本編碼模型中,嵌入層通常包含兩個主要部分:
token embeddings和position embeddings。
在這邊我們先來看token embeddings。
#將text_encoder中的token embedding部分存儲在token_emb_layer變數中。
token_emb_layer = text_encoder.text_model.embeddings.token_embedding
token_emb_layer # Vocab size 49408, emb_dim 768
接下來我們可以印出來看看,可以看到他的大小
token_emb_layer的嵌入矩陣有49408行,每一行對應於詞彙表中的一個特定token。也就是說模型已經學會了49408個不同的token的嵌入;另外每個token的嵌入向量的維度是768。這是模型將每個token表示為的固定大小的向量。
接下來的code展示如何使用嵌入層 (token_emb_layer) 從模型中取得特定token的嵌入向量。選擇了代表"puppy"的token。
# Embed a token - in this case the one for 'puppy'
embedding = token_emb_layer(torch.tensor(6829, device=torch_device))
embedding.shape # 768-dim representation
這邊的token ID 6829,對應於詞彙表中的"puppy"這個詞。
我們透過這些觀察可以更直觀地了解模型是如何將詞彙表中的每個詞轉換成一個固定維度的向量的。
接著我們可以對提示中的所有token進行相同的操作,以獲得所有的token embeddings。
所以我們把text_input.input_ids 代入token_emb_layer
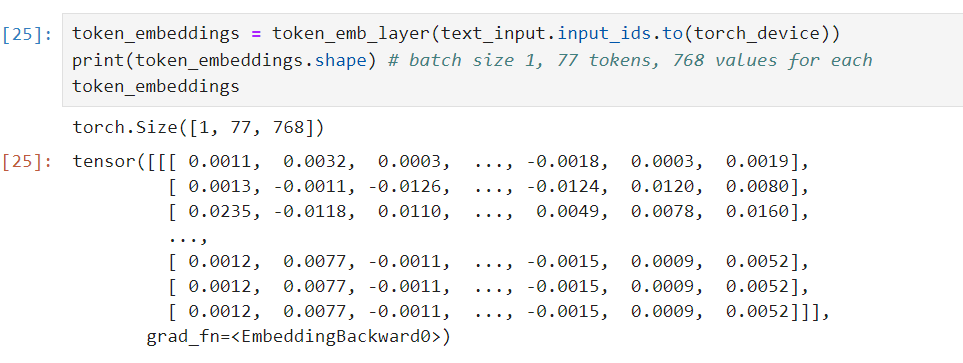
token_embeddings = token_emb_layer(text_input.input_ids.to(torch_device))
print(token_embeddings.shape) # batch size 1, 77 tokens, 768 values for each
token_embeddings
接下來我們開始討論「Positional Embeddings」,這是Transformer架構(包括BERT、GPT等模型)中的一個重要部分。
首先我們來理解Positional Embeddings的目的:
在自然語言處理中,單詞或token的位置往往非常重要。例如,句子"Tom chased Jerry"和"Jerry chased Tom"中的詞語是相同的,但其意義因為詞序的不同而有很大的區別。因此,模型需要有一種方式來了解每個token在句子中的「位置」
由於Transformer模型使用自注意機制,它們在原始設計中無法識別token的順序。因此,我們需要添加額外的信息來指示每個token的位置。這就是Positional Embeddings的作用。
正如我們之前從模型中獲取token embeddings一樣,我們現在也可以從模型中獲取positional embeddings。讓我們看筆記本中的程式:
pos_emb_layer = text_encoder.text_model.embeddings.position_embedding
取法跟之前一樣,這個物件也提供我們取得position_embedding的方法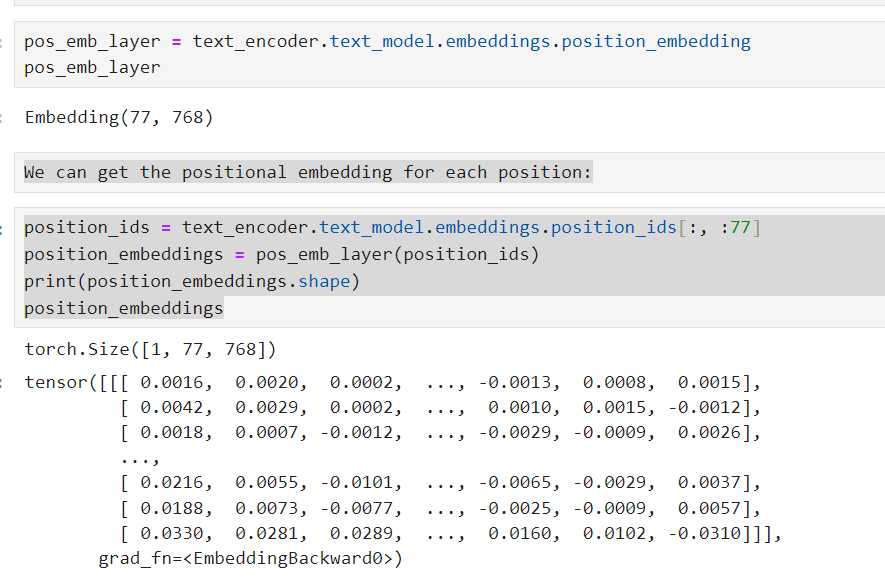
從輸出Embedding(77, 768)可以看出,這個嵌入層有77個不同的位置,每個位置都有一個768維的向量表示。這意味著模型可以處理最大長度為77的輸入序列。
Positional Embeddings確保了模型不僅僅是看到token本身,還能夠看到它們在輸入序列中的位置。在這段程式中,我們看到模型如何為每個輸入序列中的位置生成唯一的嵌入向量。這些向量為模型提供了每個token在序列中的位置訊息
將token embeddings和positional embeddings組合的最簡單方法是直接相加。
雖然有其他方法可以組合這兩種嵌入,但在這個模型中直接選擇了相加的方法。
input_embeddings = token_embeddings + position_embeddings
然後我們看一下加完之後長什麼樣,並且確定大小沒有改變(與相加之前)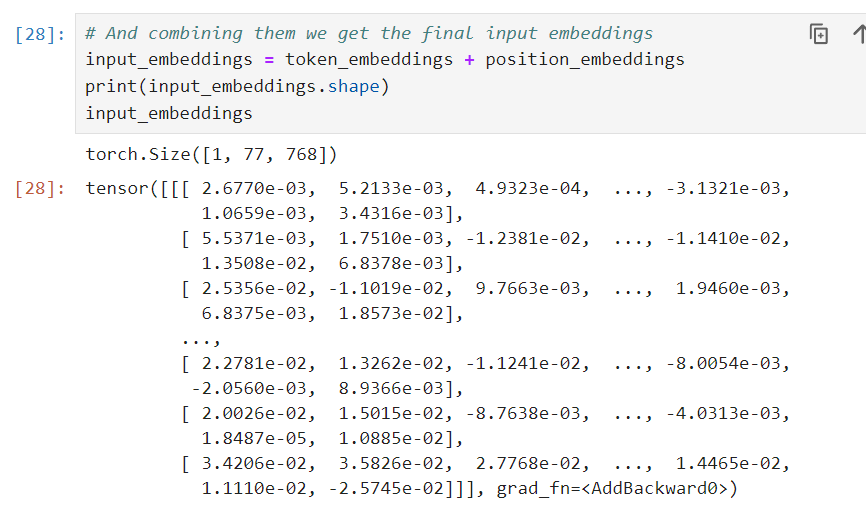
接下來我們可以驗證一下,我們手動組合token embeddings和position embeddings的結果是否與使用模型內建方法得到的結果相同。
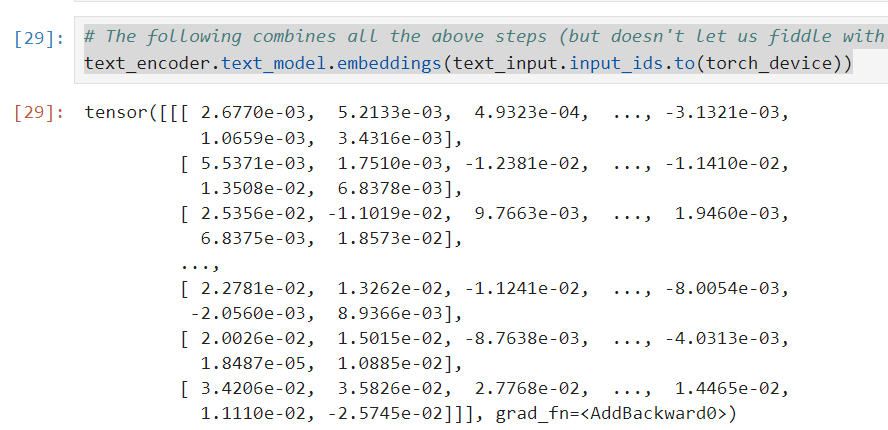
使用text_encoder.text_model.embeddings這個方法,直接將text_input.input_ids.to(torch_device)作為輸入得到嵌入結果。
text_encoder.text_model.embeddings(text_input.input_ids.to(torch_device))
輸出的tensor值可以看出,這些值與我們之前手動相加得到的input_embeddings是一致的。這意味著我們的手動操作是正確的,且與模型的內建方法給出的結果相同。
我們這邊做的步驟,剛好對應下圖的開始部份

這張圖大概可以分為3個部份來看:
在Transformer模型中,當我們有了token embeddings和positional embeddings之後,下一個步驟是將這些嵌入組合起來,然後輸入到模型中,獲取該嵌入在模型中的表示。這是因為嵌入本身只是原始數據的一個簡單表示,而我們需要模型對這些數據進行更深入的分析和理解。
上圖中,模型接收這些嵌入,並經過多個Transformer層進行處理,最終在最上面輸出encoder_hidden_states。這些輸出是模型的理解,它們包含了原始嵌入中的語義信息,經過模型的轉換和增強。
我們接下來會寫一個get_output_embeds function,這個function的目的就是完成這個過程。
給定輸入嵌入,該函數將它們輸入到模型中,並獲取encoder_hidden_states作為輸出。這些輸出嵌入可以用於各種下游任務,如文本分類、生成等。
所以說get_output_embeds 函數會是一個用於獲取模型對輸入嵌入的理解或表示的橋樑也就是取得輸入嵌入在經過Transformer文字編碼器模型後的輸出嵌入。
這是Transformer模型的核心工作流程的一部分。
那實際上應該怎麼做呢?
先看一下流程:
所以我們來看一下code
bsz, seq_len = input_embeddings.shape[:2]
causal_attention_mask = text_encoder.text_model._build_causal_attention_mask(bsz, seq_len, dtype=input_embeddings.dtype)
這裡,我們首先取得輸入嵌入的批次大小(bsz)和序列長度(seq_len)。然後,我們使用這些尺寸建立一個因果遮罩。因果遮罩確保模型在預測某個位置的token時,只能使用該位置之前的token的信息。
encoder_outputs = text_encoder.text_model.encoder(
inputs_embeds=input_embeddings,
attention_mask=None,
causal_attention_mask=causal_attention_mask.to(torch_device),
output_attentions=None,
output_hidden_states=True,
return_dict=None,
)
inputs_embeds: 我們先前得到的輸入嵌入。
attention_mask: 這是一個常見的遮罩,但在這裡我們不使用它,所以設為None。
causal_attention_mask: 我們先前創建的因果遮罩。
output_hidden_states: 設置為True,因為我們希望得到每一層的輸出,而不僅僅是最後的輸出。
在這邊我們將輸入嵌入和因果遮罩一起傳遞給模型。也設置了output_hidden_states=True,這樣模型會返回每一層的輸出嵌入,而不只是最終的預測結果。
output = encoder_outputs[0]
最後我們將這些輸出通過一個layer normalization步驟,以確保數據的穩定性。
output = text_encoder.text_model.final_layer_norm(output)
這一步確保模型的輸出在所有層之間都有一致的比例和分佈。
所以我們寫完這個function ,我們要確認一下這些輸出的嵌入與我們在筆記開頭看到的 output_embeddings 是否相匹配。
所以我們來call看看
我們成功地分解了先前單一的步驟,這樣我們可以更容易地進行修改或進一步的研究。


 iThome鐵人賽
iThome鐵人賽